
1. 概述
操作系统作为计算机硬件的管理软件直接运行在物理硬件之上,完全占有全部的硬件资源。自1965年以来,半导体硬件一直遵循摩尔定律快速发展。 硬件的计算能力不断增强,一套硬件上运行一个操作系统就显得有些浪费,这种现象在数据中心尤为明显。于是如何共享和整合硬件资源,提升硬件利用效率就成了一个需要解决的问题,虚拟化技术便应运而生。最近十几年,随着云计算的快速发展,虚拟化技术广泛应用于数据中心,已经成为云计算的核心技术之一。
虚拟化需要解决三个基本问题,共享,隔离 和 性能。在一套硬件环境上运行多个系统来共享硬件资源提升硬件利用效率是虚拟化的出发点,系统之间相互隔离保证安全是一种基本需求,操作系统运行在虚拟化的环境之上性能会有所下降,如何提升虚拟化的性能,一直伴随着虚拟化的发展。虚拟化经历了 二进制翻译,半虚拟化,硬件辅助虚拟化 的发展。现代CPU基本都已经支持硬件辅助虚拟化。那么,如何实现一个简单的硬件辅助虚拟化系统呢?
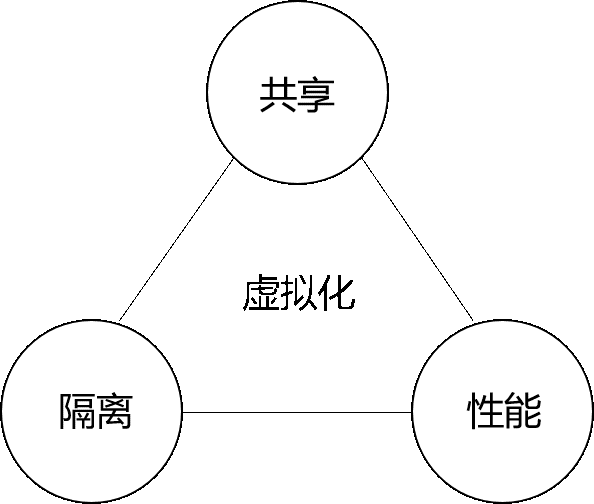
图1:虚拟化要解决的问题
ASOR, 是一个简单的虚拟化管理软件(VMM),用来帮助人们了解硬件辅助虚拟化的基本概念以及虚拟化管理软件的实现。虚拟化管理软件又被称作Hypervisor,有些文献将Hypervisor分成TYPE 1和TYPE 2两种类型,如图2所示。所谓TYPE 1类型也就是Hypervisor直接运行在硬件上,虚拟操作系统运行在Hypervisor之上,而TYPE 2类型的Hypervisor则运行在一个被称之为HOST的操作系统之上,其上再运行虚拟操作系统。其实,如果把TYPE 2中的HOST操作系统与hypervisor并成一个整体来看,这个整体也可以认为是一个TYPE 1的 Hypervisor。实现一个简单的TYPE 1类型的Hypervisor和实现一个简单的操作系统类似,前者比后者多了虚拟化的软件支持。从这个意义上,ASOR作为一个TYPE 1的Hypervisor也可以用来学习研究如何实现一个简单的操作系统。
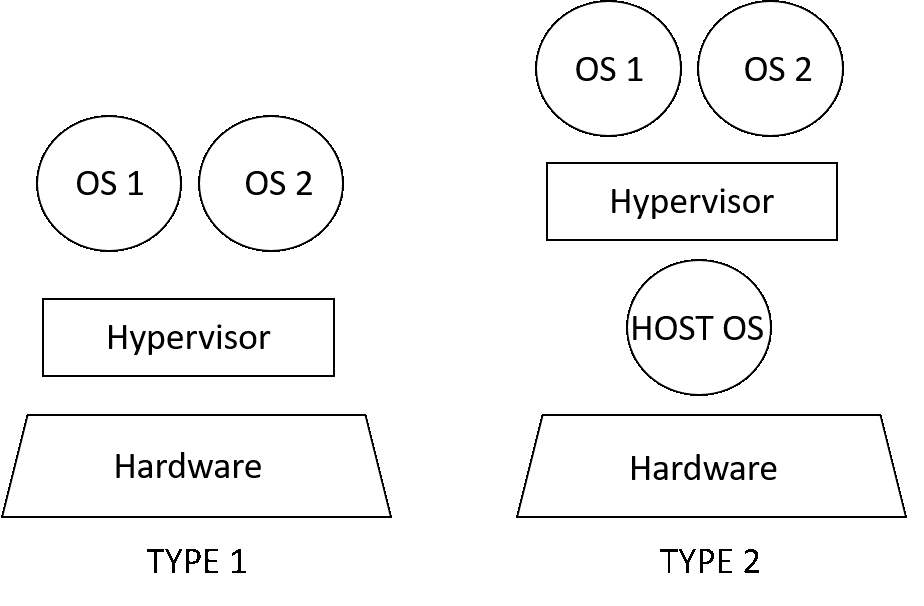
图2:虚拟机类型 TYPE 1 vs TYPE 2
支持虚拟化的硬件架构
用户态,内核态,特权指令,敏感指令
x86架构提供四个特权级别给操作系统和应用程序来访问硬件,从Ring 0 到 Ring 3。 其中Ring 0为最高级别,Ring 3为最低级别。计算机指令可以分成特权指令和非特权指令。操作系统内核代码在最高级别Ring 0上运行,可以执行特权指令直接访问硬件,而应用程序代码运则行在Ring 3上,只能执行非特权指令,这些指令不能做受控操作。当一个应用程序需要访问硬件时,需要通过执行系统调用,CPU的运行级别从Ring 3 转换到 Ring 0,并跳转执行内核代码来完成硬件访问,访问完成后再从Ring 3切回Ring 0。这个过程被称作用户态和内核态切换。计算机指令还可以划分成敏感指令和非敏感指令。所谓敏感指令,指的是那些会改变系统硬件资源配置的指令或其执行的行为依赖硬件资源配置的指令。一个可以虚拟化的硬件架构需要满足的条件是,敏感指令集必须是特权指令集的子集,如图3 所示。如果存在敏感指令是非特权指令,这样的硬件就存在虚拟化空洞,是不可虚拟化的硬件架构。这种硬件虽然不能完整支持辅助虚拟化,但仍然可以通过软件方法来实现虚拟化。
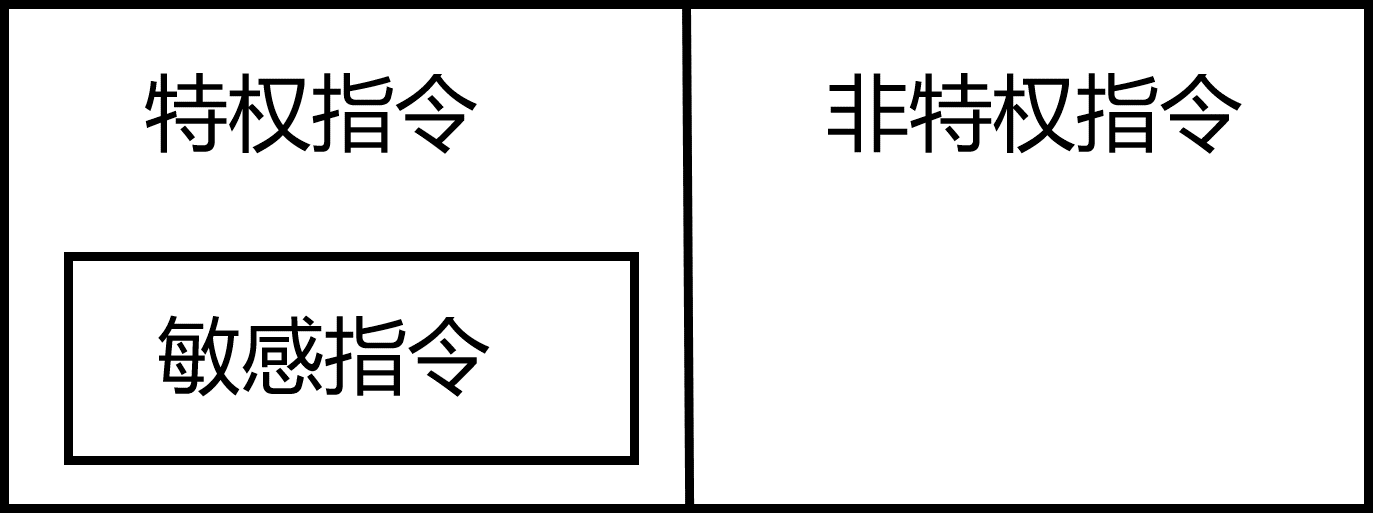
图3:可虚拟化架构
早期的硬件没有辅助虚拟化的功能。虚拟化通过修改操作系统来实现,也就是对执行的非特权敏感指令进行修改,来填补虚拟化空洞来实现虚拟化,即所谓的半虚拟化。随着硬件的发展,硬件辅助虚拟化已经成为主流。
2. ASOR的启动流程
计算机上电启动后开始执行BIOS的代码,BIOS程序首先进行硬件自检。如果硬件出问题,主板会根据具体问题发出不同类型的蜂鸣声。如果没有问题,BIOS会找到启动顺序排位第一的存储设备,读取该设备的起始扇区的512个字节。如果这512个字节的最后两个字节是 0x55 和 0xAA,表示这个设备可以用于启动,如果不是,表示设备不能用于启动,则从下一个存储设备查找。在找到可启动的设备后,控制权交给bootloader, 例如我们这里用的GRUB。通过GRUB的界面选择ASOR启动。之后程序开始执行 x86/cstart.c (对于32位系统)或 x86/cstart64.c (对于64位系统)。asor.img 是一个虚拟硬盘,用于方便在在qemu中调试ASOR。在系统中安装qemu-kvm后,运行 make qemu 便可看到如 图4所示的ASOR启动界面。
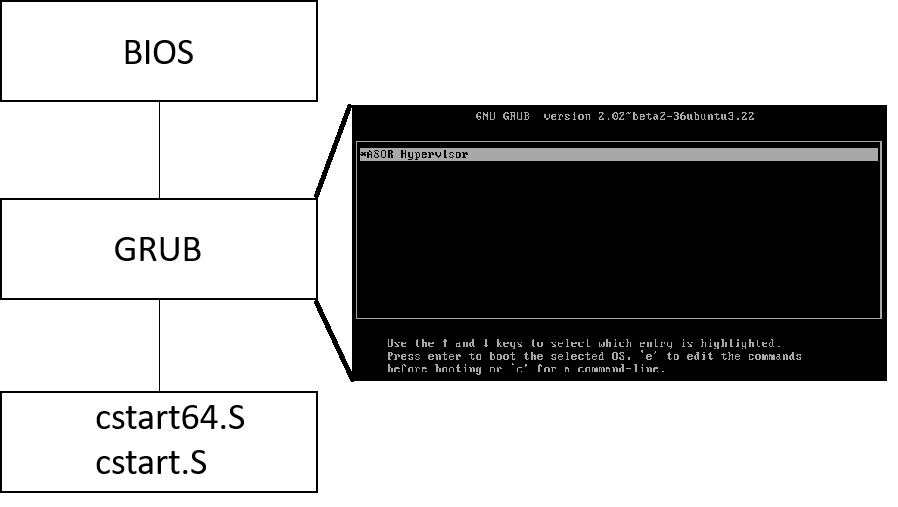
图4:ASOR启动流程
以x86/cstart.c为例,其中start标记的地址是AOSR启动代码的入口地址。从start启动代码的入口地址到ASOR C语言的main函数asor_entry的流程如图5所示。
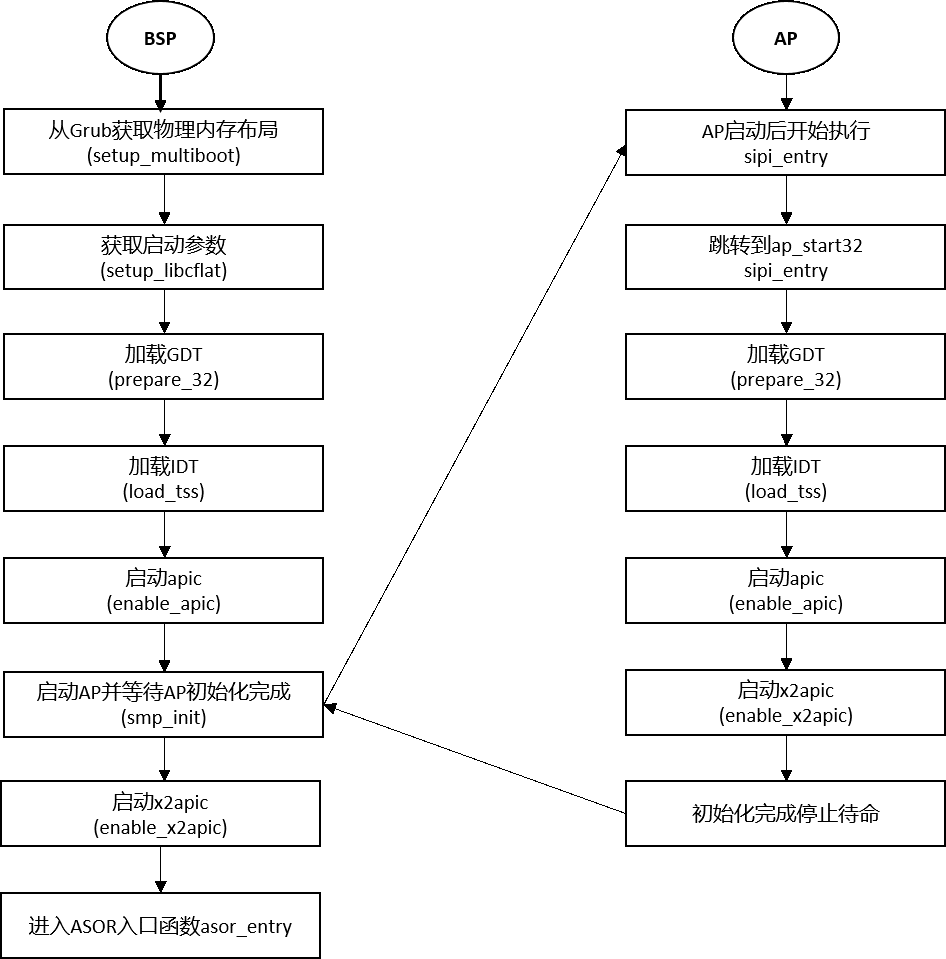
图5:从start入口到asor_entry
3. 分段与分页
x86体系结构中CPU看到的地址是逻辑地址,经过分段单元后逻辑地址被转换为线性地址,又叫虚拟地址,最后分页单元再将虚拟地址转换为物理地址,如图6。操作系统为了隔离内核空间与用户空间,通常都会定义四个段,这些段相互重叠都从地址0起始,覆盖整个线性地址空间。在特权级0上定义内核空间代码段和内核空间数据段,在特权级3上定义用户空间代码段和用户空间数据段。以此来将操作系统与用户程序隔离开来,然后再通过为每一个进程创建不同的页表来将不同的进程彼此隔离开来。图7展示了分段与分页是如何结合起来运行的。

图6:逻辑地址,线性地址(虚拟地址),物理地址
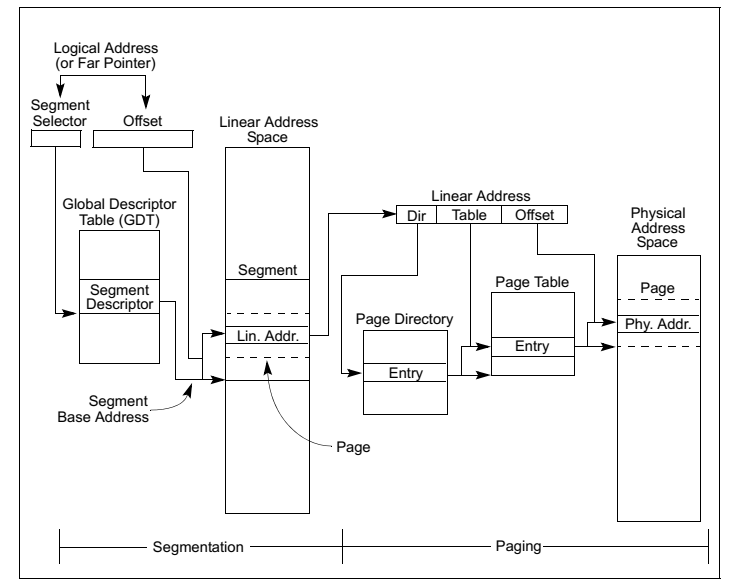
图7:分段与分页机制
多级页表
在早期32位时代广泛使用的是两级页表模式如图8图9所示,而现代64位 CPU多采用四级页表模式如图10,图11,图12所示。为什么需要多级页表呢?主要是为了节约内存。我们可以做一个简单计算。假设我们在一个32位的系统使用一级页表,每页占 4K 大小,那么为了寻址 4G 空间,我们需要 1M 个页表项,如果每个页表项占4个字节,那么我们需要一共 4M 的大小来存储页表。假如我们有100个程序,每个程序使用不同的页表,那么则一共需要 400M 来存储页表。而如果使用二级页表,第一级页表需要 4K 大小,可以存储 1K 个页目录项,每个页目录项指向一个 4K 大小第二级页表,则我们一共需要 4K+4M 的大小。这岂不是比一级页表使用的 4M 要多了吗?事实上,得益于计算机理论中的局部性原理,第二级页表并不需要全部都存在,可以按需分配,4K+4M只是最坏的情况,最少的情况下我们只需要4K+4K内存,这样100个程序在最少的情况下只需要 800KB,这比一级页表的 400M 要小得多。对于100个程序而言,两级页表需要的内存介于 800KB ~ 400K+400M 之间,大多数情况下远小于 400M。 此外,使用多级页表的好处还在于,两级及其以后的页表可以不存放在内存而存放于磁盘,需要的时候再交换回内存。
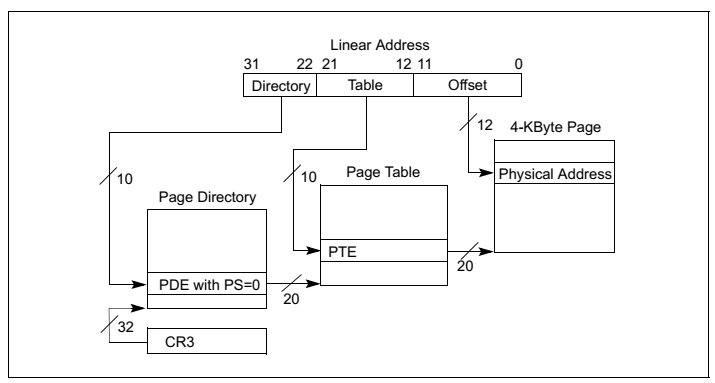
图8:采用4KB页面大小的两级页表模式
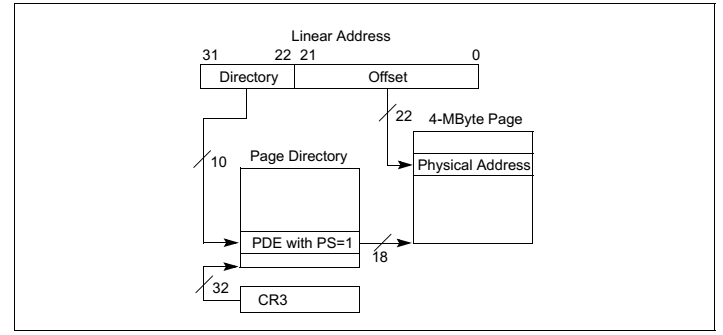
图9:采用4MB页面大小的两级页表模式
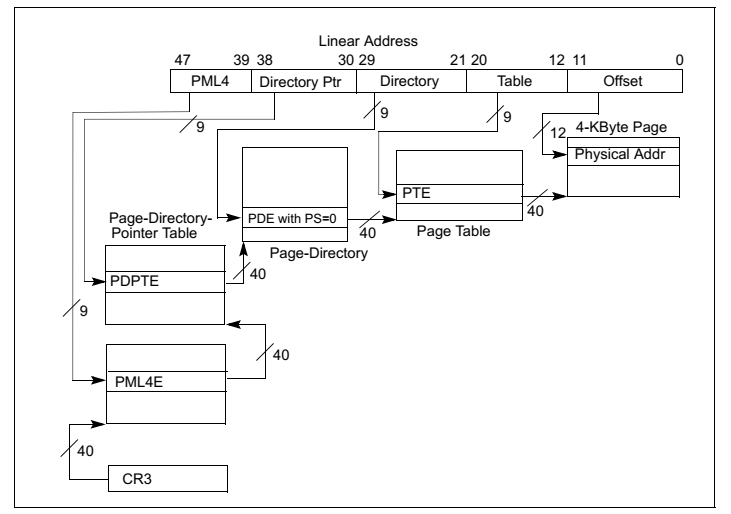
图10:采用4KB页面大小的四级页表模式
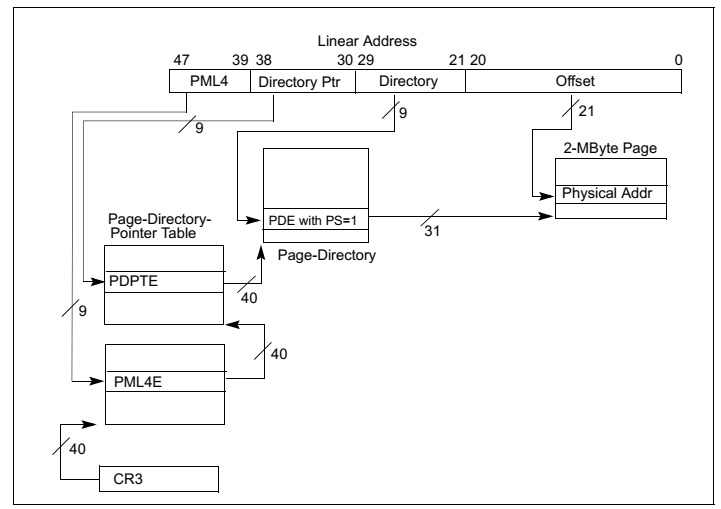
图11:采用2MB页面大小的四级页表模式
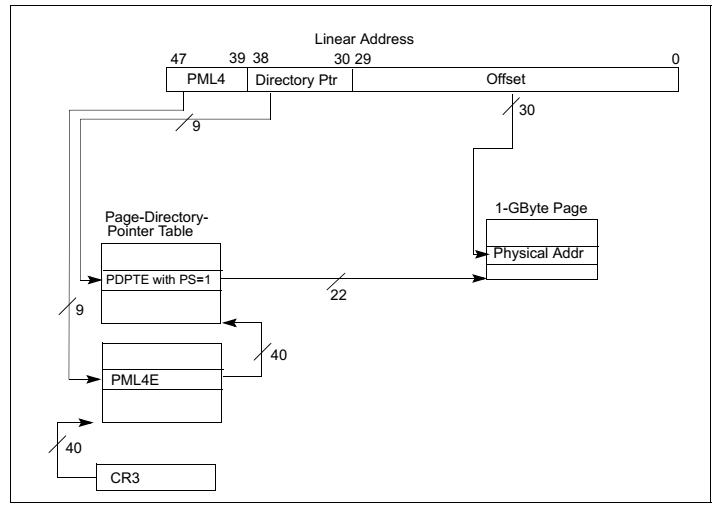
图12:采用1GB页面大小的四级页表模式
ASOR用到了四级页表模式,具体映射如图13所示,静态映射是程序初始化时就建立好的页表,而动态映射是按需建立和删除页表。

图13:内存映射
4. 中断与异常
中断作为一种异步机制被广泛采用。理解中断主要是理解两部分内容,即,中断控制器如何发送中断给CPU以及CPU收到中断后如何处理。前者主要涉及,PIC, APIC (LAPIC, I/O APIC), MSI/MSI-X,后者主要就是IDT中断描述表。我们这里暂时只讨论后者。
IDTR是一个寄存器,存有IDT表的基地址和长度。当CPU从中断控制器收到中断号后,便可以通过IDTR来找到IDT中对应的中断门(一个8个字节的描述符,如图14)。通过这个中断门可以在全局描述符中找到对应的描述符,最后找到对应的中断处理函数的逻辑地址,再结合前面的分段与分页的机制找到中断处理函数的实际物理地址跳转执行。具体流程如图15所示。
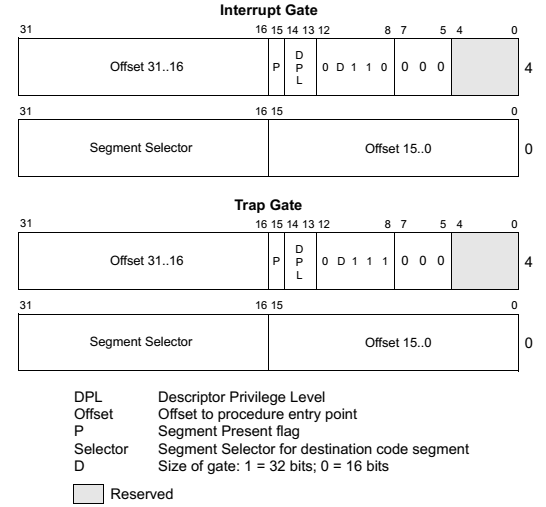
图14:中断/陷阱门
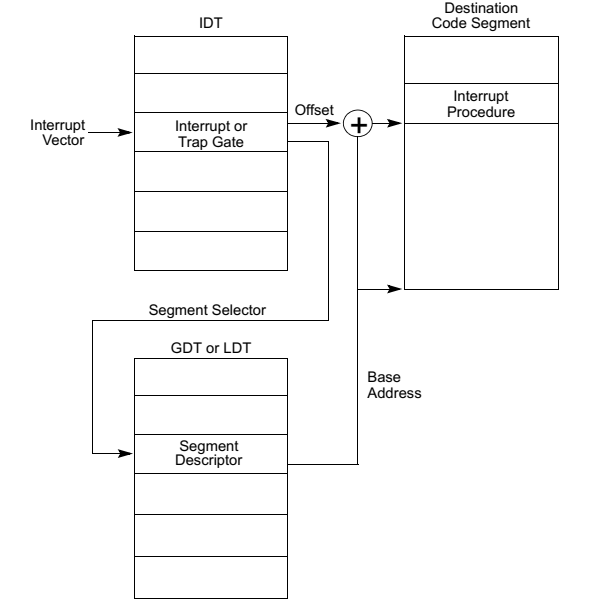
图15:CPU收到中断后处理流程
x86体系结构一共有256个中断号(0 ~ 255),其中 (0 ~ 31) 保留给体系结构定义的异常使用,见表 2,(32 ~ 255)为用户自定义外部中断。异常一般可以分为四种,即 中断(Interrupt),陷阱(Trap),故障(Fault),终止(Abort),其区别如表 1所示。
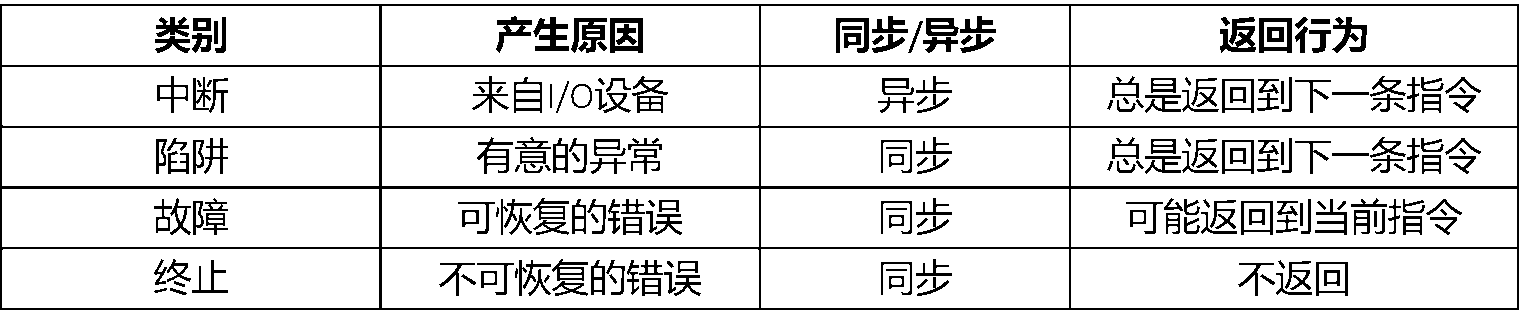
表1:异常的种类及比较
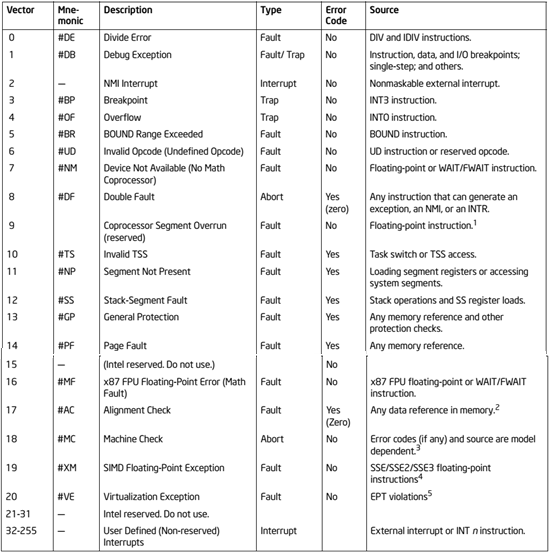
表2:x86保留中断号
一个简单的外部中断软件处理流程通常会是如图16所示。首先定义一系列 IRQ(N) 函数,将这些函数的地址填写到中断描述表对应 IDT(N) 位置。这些 IRQ(N) 有着差不多的实现,可以用一个统一的模板来定义,主要就是保存调用前的必要的上下文,调用一个通用的处理函数假设叫做common_handler,这个函数里需要完成一些通用的处理比如send EOI,除此之外,最重要的就是调用 handler(N),handler(N)是用户通过类似 register_irq(N, handler) 的用户接口注册的处理函数。最后还需要恢复调用前的上下文继续执行。对于其他异常也是类似的流程。

图16:中断软件处理
5. x86虚拟化扩展(VMX)
我们知道,只有特权指令才能运行在ring0上。在引入虚拟化之后,guest操作系统同样也存在ring0 ~ ring3。然而按照概述中可虚拟化架构的定义,guest操作系统的ring0显然不能有运行特权指令的权限。x86对此给出的解决方案是引入root和non-root模式(见图17)。guest操作系统运行在non-root模式下,虚拟机管理软件运行在root模式下。这样即便是运行在non-root模式下的ring0的指令,也可以由硬件截获并重新加以模拟。在VM中执行特权指令时,触发VM Exit回到root模式,特权指令执行完之后通过VM Entry进入Non-Root的guest继续执行。
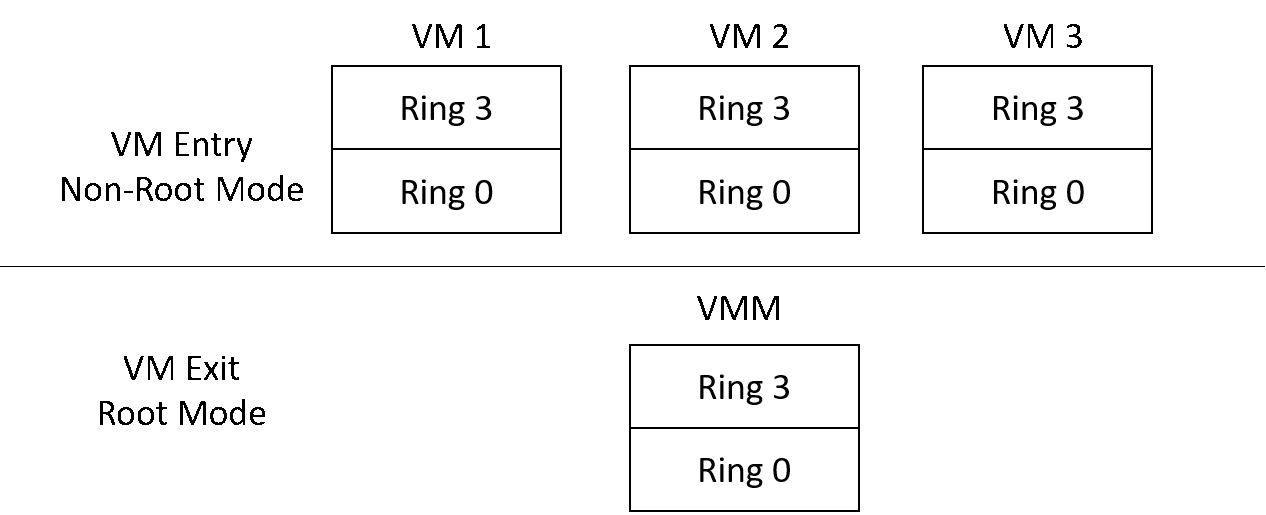
图17:Root / Non-Root 模式
VMX一共引入了13条指令如表3,包括5条指令用于 控制管理VMCS结构 (VMPTRLD, VMPTRST, VMCLEAR, VMREAD, VMWRITE),4条指令用于 管理VMX操作 (VMLAUNCH, VMRESUME, VMXON, VMXOFF), 2条指令用于 TLB 管理(INVEPT, INVVPID), 2条指令 供Guest软件调用VMM服务使用 (VMCALL, VMFUNC)。
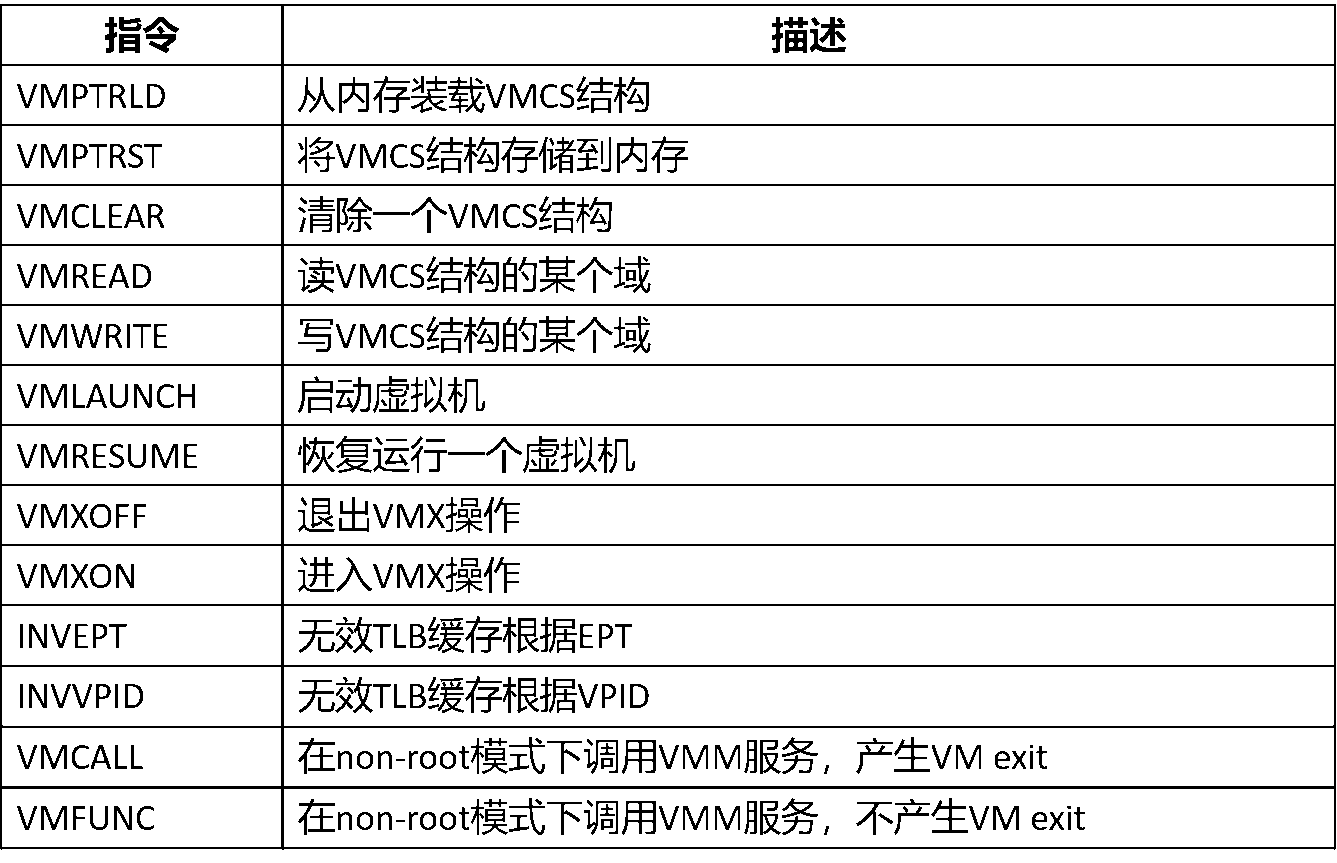
表3:VMX指令
VMM软件的生命周期如图18所示
- 软件通过执行VMXON指令进入VMX操作。
- VMM软件可通过执行VMLAUNCH或者VMRESUME发生VM entry进入Guest,在Guest发生VM exit后VMM软件重新获得控制权。
- VMM软件可以在VMCS结构中指定进入Guest的入口点以及Guest发生VM exit的入口点,VMM在执行完VM exit的相应处理后可以重新通过VM entry进入Guest。
- VMM软件可以决定是否退出VMX操作,通过运行VMXOFF指令来实现。
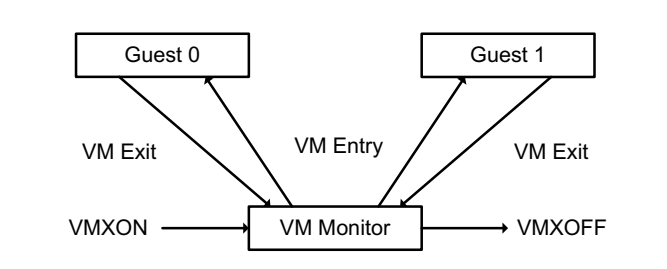
图18:VMM软件生命周期
具体软件处理流程如图19所示。当执行vmx_run()后,就会运行Guest代码,如果运行Guest代码发生VM EXIT,便针对具体原因做相应处理。

图19:VMM软件处理流程
6. 虚拟机控制结构 (VMCS)
虚拟机控制结构(VMCS,图20), 是x86硬件辅助虚拟化提供的用于软硬件交互的数据结构。这块区域又被细分为六块子区域,分别是:
- 客户机状态区域(Guest-state area): 当Guest发生VM EXIT时,会将当前的一些状态信息存储到这个区域,当下次VM Entry时,从这里加载状态信息继续运行。
- 主机状态区域(Host-state area): 当Guest发生VM EXIT进入VMX-root时,从这块区域加载运行状态信息开始运行。
- 虚拟机执行控制域(VM-execution control fields):控制处理器在VMX non-root模式下的行为,决定是否产生VM exits。
- 虚拟机退出控制域(VM–exit control fields): 控制VM exits时的行为。
- 虚拟机进入控制域(VM–entry control fields): 控制VM entry时的行为。
- 虚拟机退出信息域(VM-exit information fields): 包含虚拟机退出的原因。
虚拟机执行控制域, 虚拟机退出控制域,虚拟机进入控制域有时也被统称为 VMX控制域。
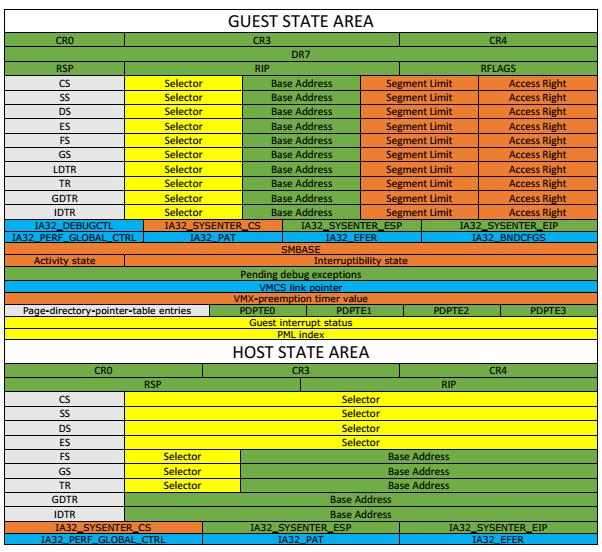
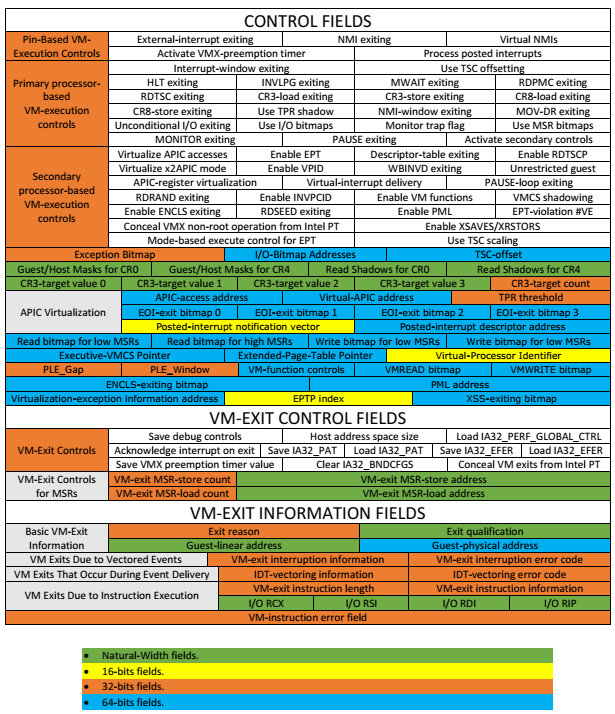
图20:VMCS结构
在首次执行客户机代码之前,可以通过客户机状态区域中的RIP,来指定客户机代码的起始执行地址。
7. 虚拟化地址转换扩展 (EPT)
早期的地址访问虚拟化通常通过影子页表的方式来实现。所谓影子页表,也就是对每一个客户机的页表在VMM中建立一个与之对应的影子页表。如图21所示。
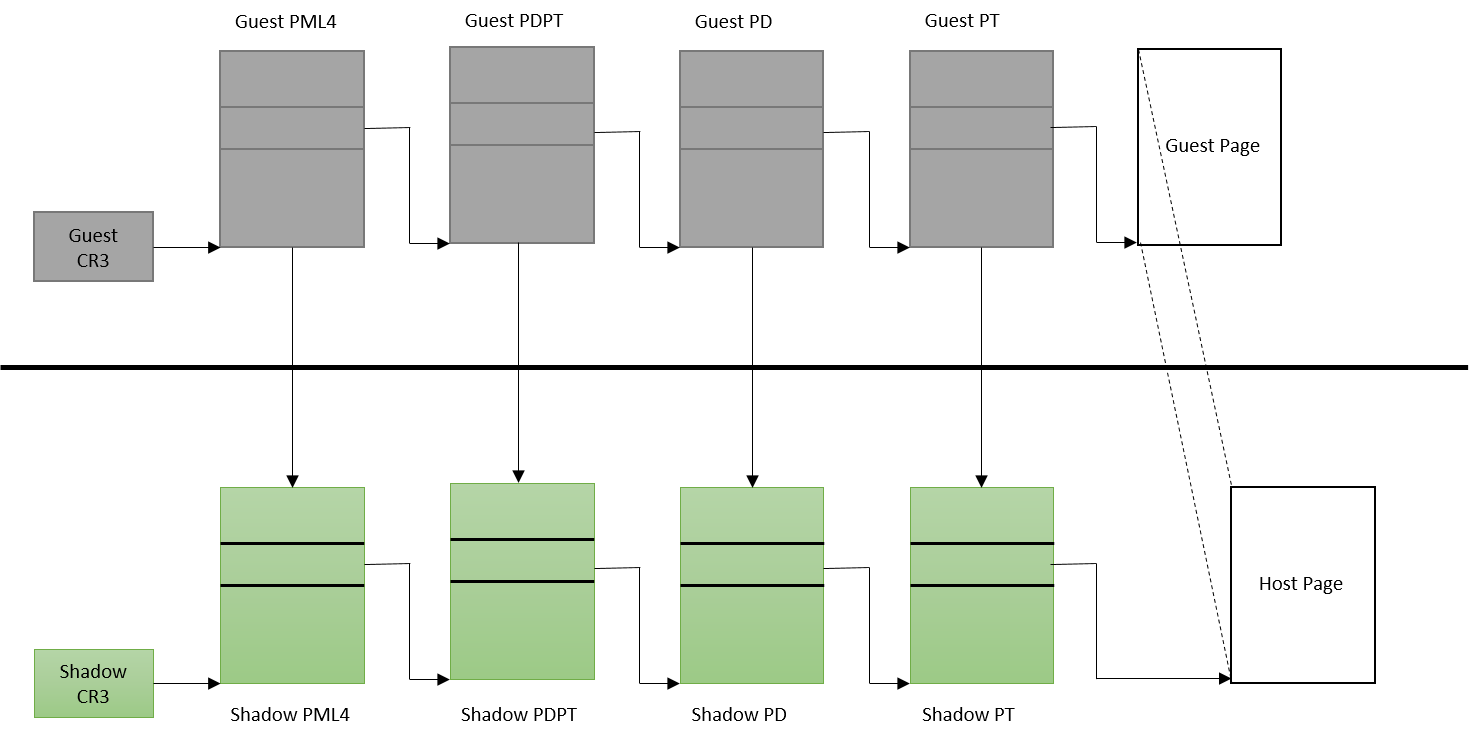
图21:影子页表
由于影子页表的虚拟化地址转换在其实现上的复杂性以及大量的VM exits和TLB flush导致的性能问题,现代虚拟化系统已经不再使用影子页表,取而代之的是硬件辅助扩展分页(Extended Page Table)。客户机操作系统维护一张页表用于将客户机虚拟地址(GVA)转换为客户机物理地址(GPA),VMM软件维护一张页表用于将客户机物理地址转(GPA)换为真正的物理地址(HPA)。当发生内存访问时,客户机可以通过这两张表直接获得真正的物理地址。其原理如图22所示。
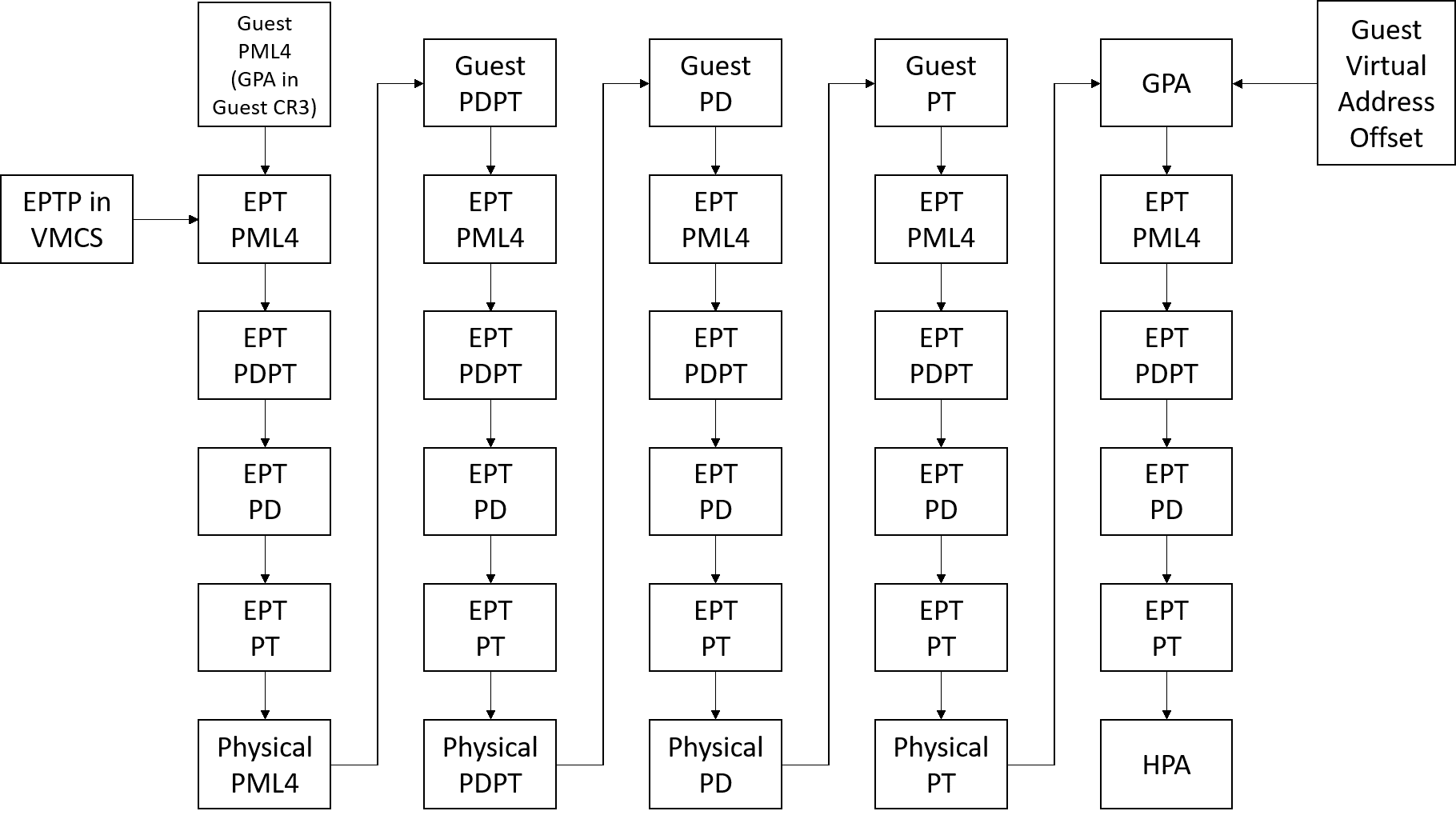
图22:EPT原理
// 待续